Tidy Tuesday
“Tidy datasets are all alike, but every messy dataset is messy in its own way.” Hadley Wickham
We live in a messy world. But for one day each week you have the opportunity to clean it up a little - to straighten the edges, iron out the creases, and make beautiful the unloved. That opportunity is Tidy Tuesday.
Tidy Tuesday (excuse me, #TidyTuesday) is a weekly initiative from the R for Data Science online learning community (inspired by the R for data science text by Hadley Wickham and Garret Grolemund). It began life in 2018 and its purpose is to encourage R users to flex their tidyverse muscles on a new dataset each week. Subjects for investigation have ranged from alcohol consumption habits around the world to Californian Wildfires. What you do with the data is up to you! You might want to perform an in depth statistical analysis, or you might want to recreate a data visualisation (each week’s dataset comes with an accompanying article). You are encouraged to post not only your output, but also your code (of course hashtagging appropriately) so all participants can share in the bounty the tidyverse has to offer.
You might be thinking “Tuesdays don’t really work for me, that’s yoga night.” Never fear! Tidy Tuesday is more a state of mind than a prescriptive task. Rarely have I completed it on a Tuesday, and there’s nothing stopping you going back into the archive and plucking out an older dataset. #TardyTuesday anyone?:
@sastoudt coined the catch-all phrase "#tardyTuesday " - a tidytuesday in any other day! 😜
— R4DS online learning community (@R4DScommunity) November 7, 2018
Participating in Tidy Tuesday has been immensely helpful in my development as an R programmer/analyst. I started learning R and the tidyverse in earnest around March last year, using the R4DS book and the wonderful courses at DataCamp. At the same time I started following #rstats people on Twitter and discovered Tidy Tuesday in it’s infancy. After a few weeks of watching other people’s efforts, I decided to take the plunge. I cannot stress enough how instrumental it has been in my progress over the last year, and I want to give a big thanks to all involved, especially Thomas Mock who keeps the Tidy Tuesday show on the road.
I’ll now pick out some of my contributions from last year in an attempt to show my development. I’ll do this to hopefully encourage anyone new to R to take the plunge themselves and participate in this wonderful project. No contribution is too small, and everyone has to start somewhere. The #rstats community is super supportive, and who knows, you might just teach someone something they didn’t know!
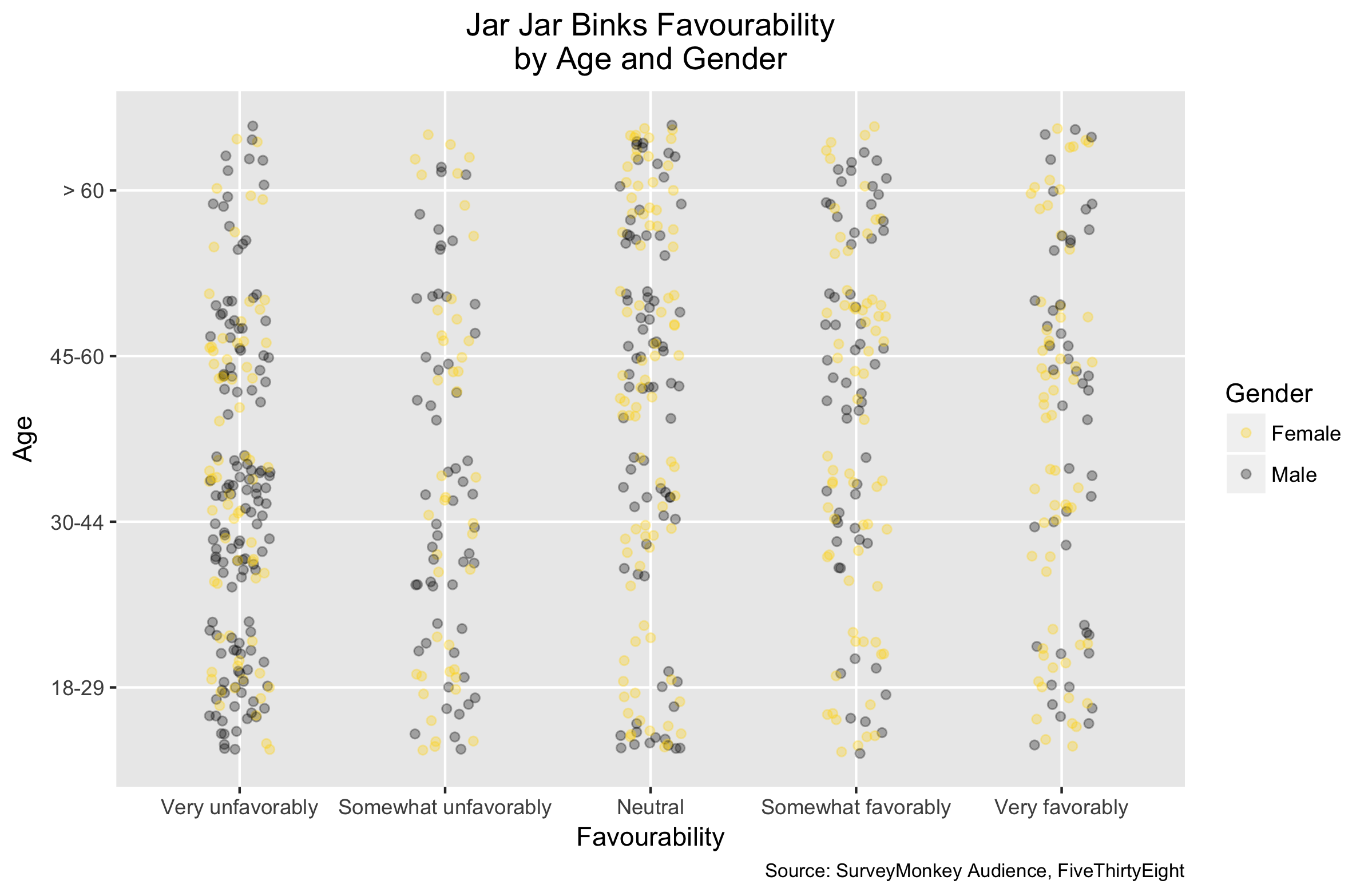
Week 7 - Star Wars
My first contribution was 7 weeks into the project. I am by no means a Star Wars buff, but I am all too aware of people’s dislike for Jar Jar Binks. Perhaps no surprise that Males aged 18-44 showed a particular disdain:
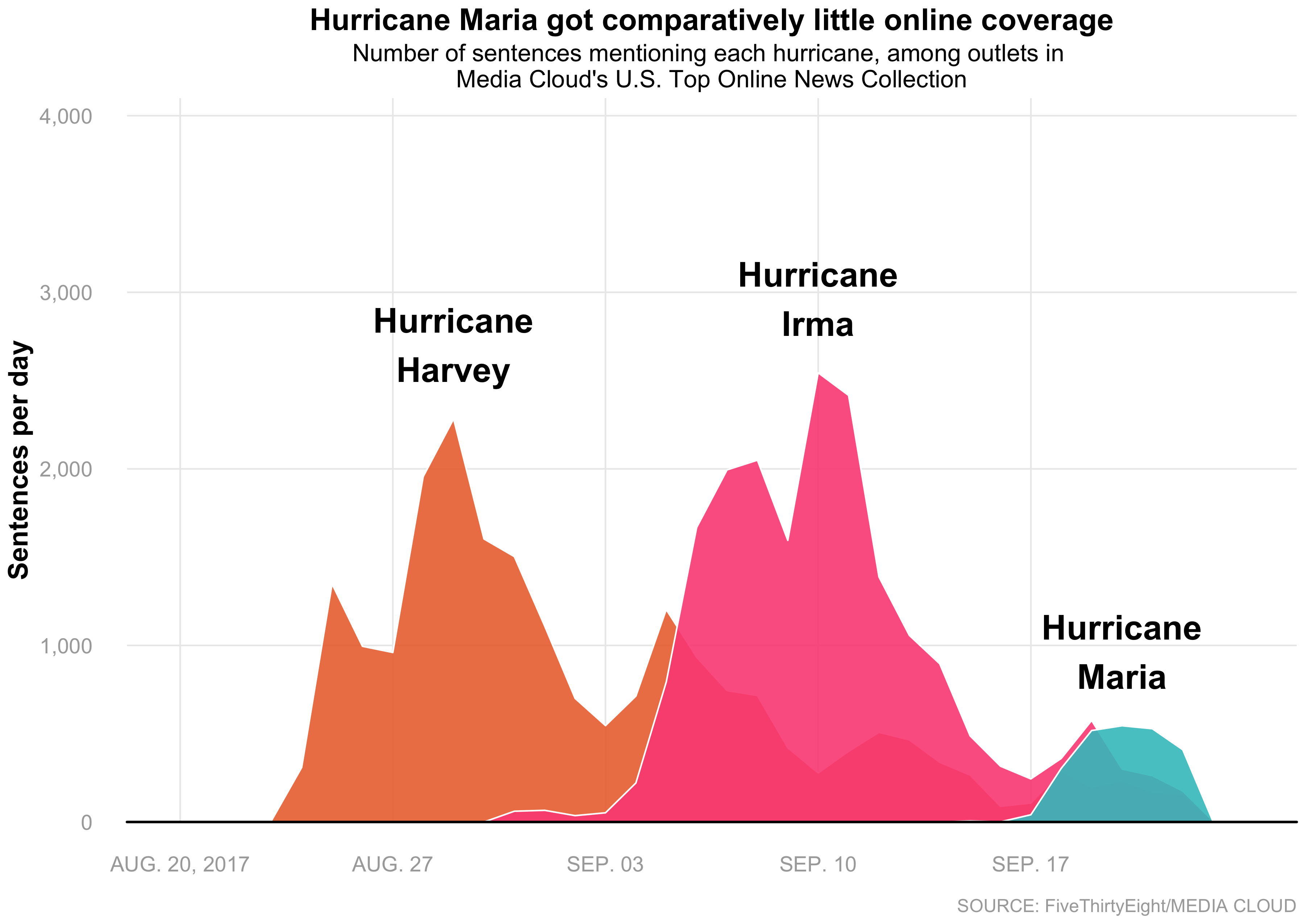
Week 12 - Hurricanes & Puerto Rico
In week 12 I took a stab at re-creating a plot from the FiveThirtyEight article that the data was sourced from. I find studying a graph (or even an album cover) and working out how to create it in ggplot2 really fun, and it’s a great way to practice customising plots using the elements of ggplot2:
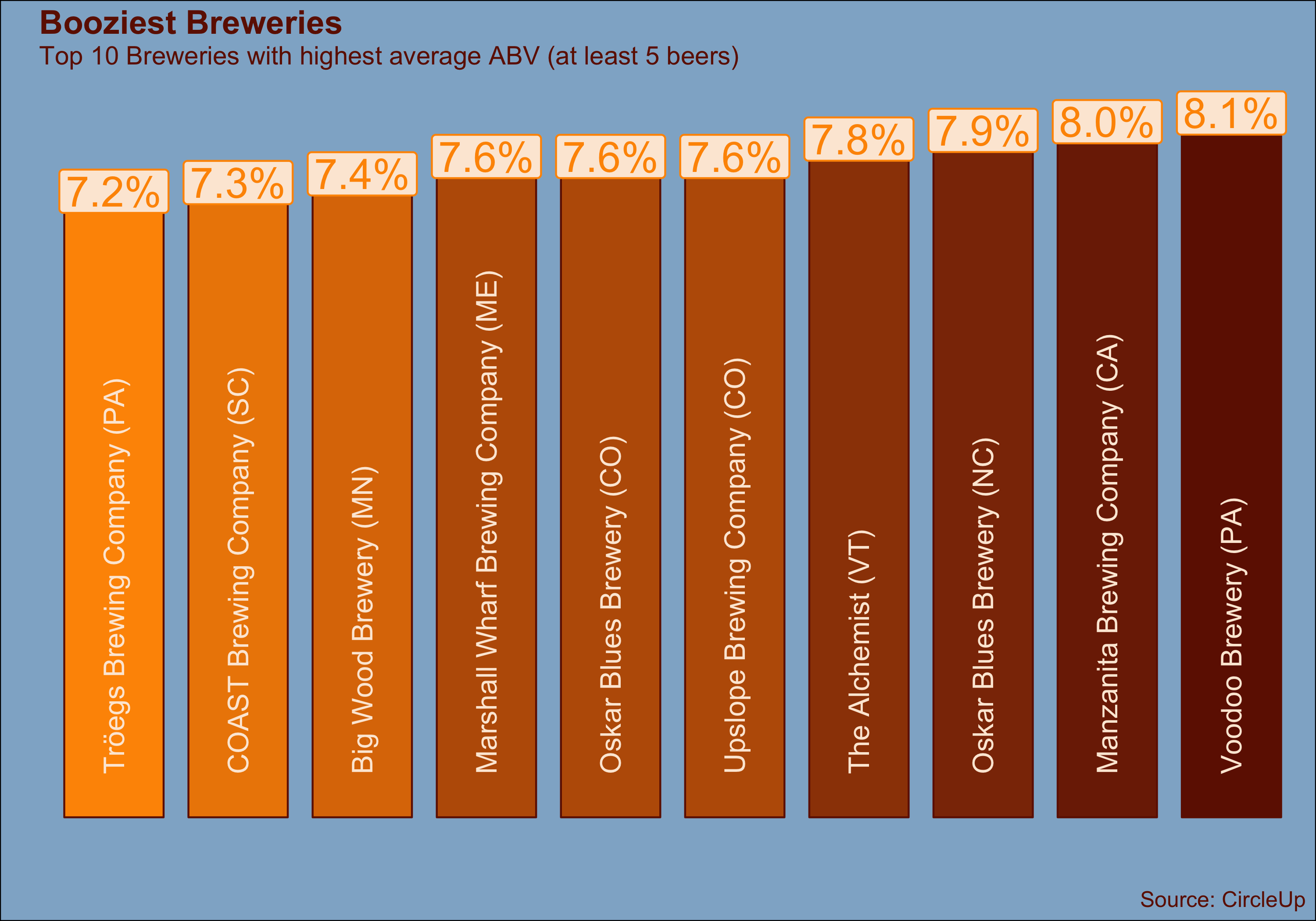
Week 15 - Craft Beer USA
Week 15 left me a little thirsty. I decided to continue my journey into ggplot2 customisation, creating what I like to call a Beerchart (patent pending):
Week 18 - Dallas Animal Shelter
In week 18 I moved onto exploring other visualisation packages that play nicely with the ggplot2 principles. I have taken Tidy Tuesday as an opportunity to try out packages for the first time. I love the look of alluvial diagrams, and as luck would have it, the ggalluvial package does the job:

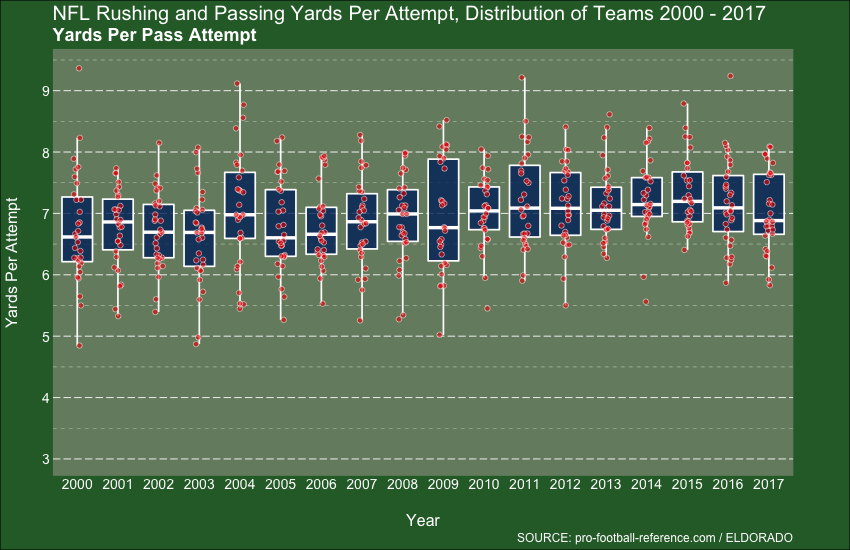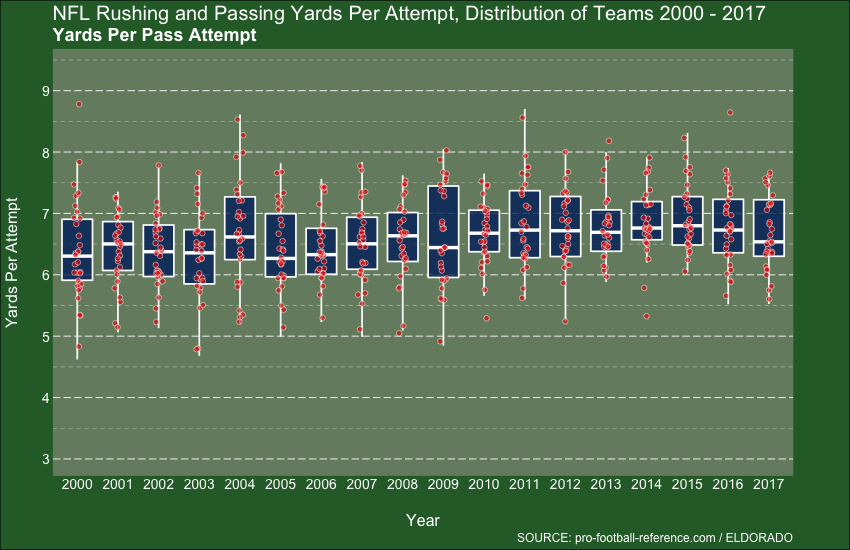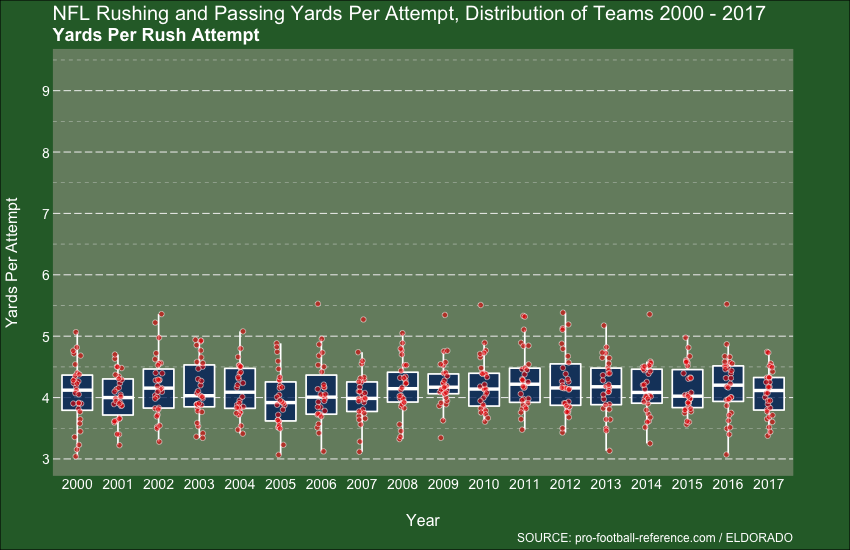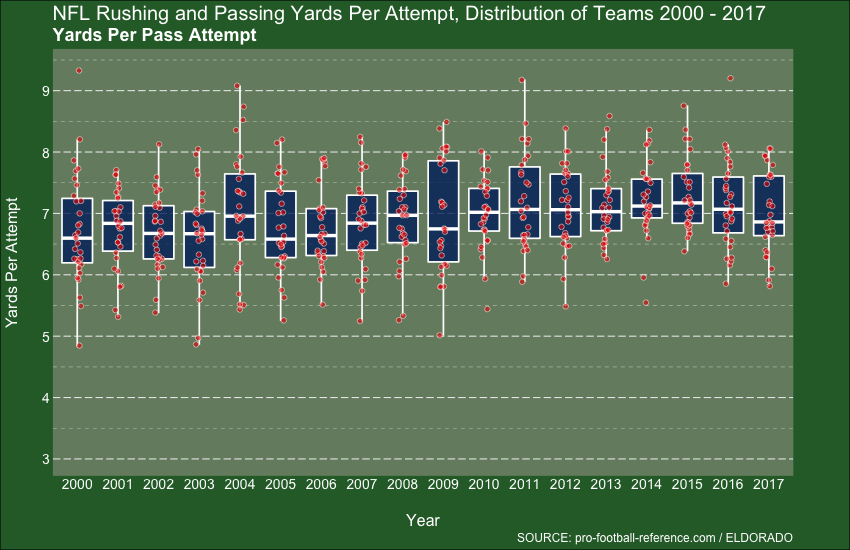
Week 22 - NFL Stats
I’ll finish with Week 22, which takes us up to August last year. I’d used the gganimate package a few times by this point, and was actually finding it hard to not use it, it’s that cool. Alas, my knowledge of Football (American Football to me) is next to non-existent, so draw your own insights:
Why should I Tidy?
Tidy Tuesday has provided the perfect bridge from my learning activities to my first in-depth data projects. After taking part in almost every Tidy Tuesday from May to September last year, it took a backseat as I worked on my own projects. Participating in it has given me the confidence to tackle these longer-form pieces. Learning from online courses/books etc is great, but it’s not until you start implementing what you’ve learnt that it really sinks in. Tidy Tuesday not only provides you with an interesting dataset every week for you to practice your skills, but also the motivation to post your output, get feedback from others, and see how others have approached the same data. I’ve found all of this invaluable.
2019 - Tidy Tuesday 2.0
Tidy Tuesday goes from strength to strength in 2019. Thomas Mock has made the process really slick, with the data and acommpanying article being posted on Monday each week to give everyone a bit of a run up. Also, if you prefer just to watch, you can now see David Robinson, Chief Data Scientist at Datacamp, tackle the Tidy Tuesday datasets in real-time in his weekly screencast. These are an amazing insight into how an experienced Data Scientist goes about analysing previously unseen data, and I’ve already picked up some great tips from the ones I’ve watched so far.
I will dip into Tidy Tuesday throughout 2019 when the data subject piques my interest, but will continue to focus on my own projects. Nonetheless, I look forward to seeing everyone’s contributions each week, picking up new tricks from my fellow Tidy Tuesdayers and continuing to show my support.
In short, Tidy Tuesday is great, the R online community is great, and I love being a part of it!