Wes Anderson
“The truth is, neither one of us has the slightest idea where this relationship is going.” Max Fischer, Rushmore
Sure, dplyr can be pretty handy, and ggplot2 has certainly got something going for it, but I think we can all agree that the real gem amongst the plethora of R packages is the wesanderson package.
Just in case you live in a dull, pastel-free world, the wesanderson package provides a collection of colour palettes inspired by the films of Wes Anderson, initially derived from this Tumblr blog, and compiled by Karthik Ram.
I thought, why not turn the Wes Anderson-ness up a level, and use these colour palettes in a visualisation of Wes Anderson films? Here’s what I came up with.
Don’t tell me, Bill Murray’s in it
Even the casual Wes Anderson film-goer has probably noticed that certain actors tend to pop up again and again in his films. A Wes Anderson film (or any film for that matter) doesn’t really come to life until Bill Murray enters. Jason Schwartzman and Owen Wilson also gain pretty regular employment from the Wes Anderson film factory. Who else has appeared in multiple films? Has his list of regulars changed over time?
These questions are the inspiration for my visualisation, a network graph of the actors appearing in Wes Anderson’s 9 feature films to date.
Setting the scene
Along with the trusty tidyverse and the aforementioned wesanderson package, I will be using the tidygraph and ggraph packages to first construct, and then visualise the network. I will spend most of this blog post detailing my use of the tidygraph and ggraph to achieve my goal. This was my first time using them (in fact, it’s my first time doing any kind of network analysis). Both of these packages were built by Thomas Pedersen, and he provides a succinct, tweet-sized explanation of what they are:
Tidygraph is dplyr for networks - ggraph is ggplot2 for networks
— Thomas Lin Pedersen (@thomasp85) January 16, 2019
Let’s load the packages:
library(tidyverse) #for most things
library(wesanderson) #for colours
library(tidygraph) #for converting to network data
library(ggraph) #for visualising network data
library(extrafont) #for fontsI’m also using the extrafont package so I can include Wes’ font of choice, Futura.
The Data
I’ve scraped the cast list for the 9 feature films from IMDb using the rvest package. I won’t dwell on this process as I plan on covering web-scraping in another post soon. Note that I’ve removed actors that were ‘uncredited’.
library(rvest) #for web scraping
# Wes Anderson IMDB page
wesurl <- "https://www.imdb.com/name/nm0027572/"
# Read html of page
readwes <- read_html(wesurl)
# extract names of films directed
films_date <- readwes %>%
html_nodes("#filmo-head-director+ .filmo-category-section .filmo-row") %>%
html_text() %>%
# remove unwanted strings
str_remove_all("\n") %>%
str_trim()
# film names
films <- str_sub(films_date, 5, -1)
# film years
film_year <- as.integer(str_sub(films_date, 1, 4))
# extract urls of films directed
film_urls <- readwes %>%
html_nodes("#filmo-head-director+ .filmo-category-section a") %>%
html_attr('href') %>%
# remove unnecessary references after final forward slash
str_sub(1, 17)
film_urls
# combine film names and urls into dataframe
film_df <- tibble(title = films, film_url = film_urls, film_year = film_year) %>%
# remove the films that are Shorts - only considering feature length films
filter(!str_detect(toupper(title), "SHORT")) %>%
# remove anything in brackets after film title
# get full url address and append trail for the full cast location
mutate(title = str_remove(title, "\\(.*\\)"),
film_url = str_c("https://www.imdb.com", film_url),
film_cast_url = str_c(film_url, "fullcredits?ref_=tt_cl_sm#cast"))
film_df
# get vector of urls for the cast list of each film - to iterate over
cast_urls <- film_df$film_cast_url
# create function to scrape cast lists
wes_scrape <- function(url) {
Sys.sleep(3)
# read html of cast list
readcast <- read_html(url)
# get film title
film_title <- readcast %>%
html_nodes(".parent a") %>%
html_text()
film_title
# get full list of actors
actors <- readcast %>%
html_nodes(".primary_photo+ td") %>%
html_text() %>%
str_trim()
actors
# get full list of characters
role <- readcast %>%
html_nodes(".character") %>%
html_text() %>%
str_trim()
role
# create dataframe of film with all actors and the character they play
cast_df <- tibble(title = film_title, actor = actors, role = role) %>%
# remove roles that were uncredited - don't want the list of actors to get out of control!
filter(!str_detect(role, "uncredited"))
}
# iterate over the scraping function with vector of urls
all_wes <- map_df(cast_urls, wes_scrape)
# ensure no actor is listed twice for same film
wes <- all_wes %>%
distinct(title, actor) %>%
left_join(film_df, by = "title") %>%
select(title, actor, film_year)Let’s take a look at the data:
head(wes)## # A tibble: 6 x 3
## title actor film_year
## <chr> <chr> <int>
## 1 Isle of Dogs Bryan Cranston 2018
## 2 Isle of Dogs Koyu Rankin 2018
## 3 Isle of Dogs Edward Norton 2018
## 4 Isle of Dogs Bob Balaban 2018
## 5 Isle of Dogs Jeff Goldblum 2018
## 6 Isle of Dogs Bill Murray 2018tail(wes)## # A tibble: 6 x 3
## title actor film_year
## <chr> <chr> <int>
## 1 Bottle Rocket Nena Smarz 1996
## 2 Bottle Rocket Héctor García 1996
## 3 Bottle Rocket Daniel R. Padgett 1996
## 4 Bottle Rocket Russell Towery 1996
## 5 Bottle Rocket Ben Loggins 1996
## 6 Bottle Rocket Linn Mullin 1996Wes’ Favourites
Who’s appeared the most? Let’s get the actors that have appeared in at least 3 of the 9 films:
# most used actors - actors appearing 3 or more times - to be highlighted later in plot
most_used_actors <- wes %>%
count(actor, sort = TRUE) %>%
filter(n >= 3)
most_used_actors## # A tibble: 22 x 2
## actor n
## <chr> <int>
## 1 Bill Murray 8
## 2 Owen Wilson 6
## 3 Eric Chase Anderson 5
## 4 Jason Schwartzman 5
## 5 Anjelica Huston 4
## 6 Kumar Pallana 4
## 7 Wallace Wolodarsky 4
## 8 Adrien Brody 3
## 9 Andrew Wilson 3
## 10 Bob Balaban 3
## # ... with 12 more rows22 actors have appeared 3 or more times. This seems like a resonable number that could be annotated in the network graph, so I’ll use this later. Bill Murray comes out on top as we might expect.
Next I’m going to add a count for each actor (i.e. how many films has the actor appeared in?) and a count for each film (i.e. how many actors appeared in each film?):
wes_film_actor <- wes %>%
select(title, actor) %>%
add_count(actor) %>%
add_count(title) %>%
rename(actor_weight = n,
film_weight = nn)
wes_film_actor## # A tibble: 518 x 4
## title actor actor_weight film_weight
## <chr> <chr> <int> <int>
## 1 Isle of Dogs Bryan Cranston 1 49
## 2 Isle of Dogs Koyu Rankin 1 49
## 3 Isle of Dogs Edward Norton 3 49
## 4 Isle of Dogs Bob Balaban 3 49
## 5 Isle of Dogs Jeff Goldblum 3 49
## 6 Isle of Dogs Bill Murray 8 49
## 7 Isle of Dogs Kunichi Nomura 2 49
## 8 Isle of Dogs Akira Takayama 1 49
## 9 Isle of Dogs Greta Gerwig 1 49
## 10 Isle of Dogs Frances McDormand 2 49
## # ... with 508 more rowsSo you can see that 49 actors were used in ‘Isle of Dogs’ and, for example, Edward Norton has appeared in 3 films overall.
So many colours, so little time
Now let’s focus on the colours, that’s what we’re here for after all. The following code takes all the wesanderson colour palettes and puts them into a single dataframe:
# wes anderson palettes
wes_palettes <- names(wesanderson::wes_palettes)
# function to extract all colours for palettes along with palette name
wes_pal_func <- function(pal) {
col_df <- tibble(colours = wes_palette(pal), palette = pal)
}
# create dataframe of all colours and palette names
wes_colours <- map_df(wes_palettes, wes_pal_func)
wes_colours## # A tibble: 92 x 2
## colours palette
## <chr> <chr>
## 1 #A42820 BottleRocket1
## 2 #5F5647 BottleRocket1
## 3 #9B110E BottleRocket1
## 4 #3F5151 BottleRocket1
## 5 #4E2A1E BottleRocket1
## 6 #550307 BottleRocket1
## 7 #0C1707 BottleRocket1
## 8 #FAD510 BottleRocket2
## 9 #CB2314 BottleRocket2
## 10 #273046 BottleRocket2
## # ... with 82 more rowsThis gives me a column with the hex-code for each colour and a column with the associated film/palette. I’ve done this just to make it easier for me to reference the colours (they appear in this dataframe in the order they appear on the GitHub page). It’s probably best I don’t divulge how much time I spent deciding which colours to use, but I eventually picked the following 9 colours for the films, all taken from their associated colour palette:
film_palette <- rev(wes_colours[c(1, 16, 23, 32, 37, 51, 65, 75, 82), ]$colours)
film_palette## [1] "#9986A5" "#FD6467" "#F4B5BD" "#DD8D29" "#FF0000" "#3B9AB2" "#899DA4"
## [8] "#35274A" "#A42820"I’ve reversed the order here, as you may have noticed that in my data the films actually appear from last to first (Isle of Dogs to Bottle Rocket). These 9 colours will be used in the plot to colour the 9 film nodes and their emanating edges.
I have also chosen a colour to be assigned to all actor nodes:
actor_colour <- wes_colours[47, ]$colours
actor_colour## [1] "#446455"Back to the data
Why did I go off on a colour tangent? I want to add these carefully curated colours into my dataset so they can be easily and correctly mapped to their intended aesthetics in the final plot. Let’s take the wes_film_actor dataframe I created earlier and develop it so it’s ready for the network treatment. First, let’s work on the actors:
# get actor size (number of appearances) and colour for actor nodes in plot
act_aes <- wes_film_actor %>%
distinct(actor, actor_weight) %>%
rename(name = actor, weight = actor_weight) %>%
mutate(colour = actor_colour)
act_aes## # A tibble: 440 x 3
## name weight colour
## <chr> <int> <chr>
## 1 Bryan Cranston 1 #446455
## 2 Koyu Rankin 1 #446455
## 3 Edward Norton 3 #446455
## 4 Bob Balaban 3 #446455
## 5 Jeff Goldblum 3 #446455
## 6 Bill Murray 8 #446455
## 7 Kunichi Nomura 2 #446455
## 8 Akira Takayama 1 #446455
## 9 Greta Gerwig 1 #446455
## 10 Frances McDormand 2 #446455
## # ... with 430 more rowsI now have a distinct list of actors with their weight (number of appearances) and colour (same for all actors). These will be mapped to aesthetics in the final plot. I have renamed actor to name for reasons explained later.
Similarly, I will get a unique list of films with their weight (cast size) and colour (the 9 colours chosen earlier):
# get film weighting (number of cast members) for film nodes - not used in the end
# and relevant colour for film nodes in plot
film_aes <- wes_film_actor %>%
distinct(title, film_weight) %>%
mutate(film_weight = film_weight/10) %>%
rename(name = title, weight = film_weight) %>%
cbind(colour = film_palette)
film_aes## name weight colour
## 1 Isle of Dogs 4.9 #9986A5
## 2 The Grand Budapest Hotel 9.9 #FD6467
## 3 Moonrise Kingdom 5.5 #F4B5BD
## 4 Fantastic Mr. Fox 3.0 #DD8D29
## 5 The Darjeeling Limited 6.2 #FF0000
## 6 The Life Aquatic with Steve Zissou 7.7 #3B9AB2
## 7 The Royal Tenenbaums 6.2 #899DA4
## 8 Rushmore 5.0 #35274A
## 9 Bottle Rocket 3.4 #A42820I’ve divided the cast size by 10 to align it more with the actor sizes, however, in the end I decided not to use this as an aesthetic in the plot. The reasoning being that the size of each film’s cast will be visually represented by the number of actor nodes linked to each film node. Therefore, I felt this added aesthetic change was unnecessary so all film nodes in the final plot are the same size.
We now have 2 dataframes, one with unique actors and one with unique films, both containing a name, weight and colour variable. Let’s append them into one dataframe:
# weighting and colours for actors and films
actor_film_aes <- rbind(act_aes, film_aes)The Network
Why have I created this dataframe above? Hopefully all will now become clear. The time has come to turn the data into a network. I had no experience of networks when I started this project, but being a fan of all things tidy, I was drawn to the tidygraph package by Thomas Pedersen. His introduction to tidygraph was a good place to start, I especially liked the following:
There’s a discrepancy between relational data and the tidy data idea, in that relational data cannot in any meaningful way be encoded as a single tidy data frame. On the other hand, both node and edge data by itself fits very well within the tidy concept as each node and edge is, in a sense, a single observation. Thus, a close approximation of tidyness for relational data is two tidy data frames, one describing the node data and one describing the edge data.
To convert the data into the structure described above, we need to specifically create a tbl_graph object using the as_tbl_graph function (consult Thomas’ introduction for more details). Let’s first just do that to get an idea of what’s happening:
# convert dataframe to table graph object using tidygraph package
# this is made of 2 data frames: a node df and an edge df
wes_network <- wes %>%
select(title, actor) %>%
as_tbl_graph()
wes_network## # A tbl_graph: 449 nodes and 518 edges
## #
## # A directed acyclic simple graph with 1 component
## #
## # Node Data: 449 x 1 (active)
## name
## <chr>
## 1 Isle of Dogs
## 2 The Grand Budapest Hotel
## 3 Moonrise Kingdom
## 4 Fantastic Mr. Fox
## 5 The Darjeeling Limited
## 6 The Life Aquatic with Steve Zissou
## # ... with 443 more rows
## #
## # Edge Data: 518 x 2
## from to
## <int> <int>
## 1 1 10
## 2 1 11
## 3 1 12
## # ... with 515 more rowsSo we have 2 dataframes: Node Data and Edge Data. Notice that the Node Data is showing as ‘active’. This is something that was lost on me to start with. Essentially you can perform most dplyr actions to the data, but only to one of the 2 dataframes at any one time. So let’s first focus on the Node Data, as this is the active dataframe.
The Node data has just the 1 column (name) and 449 rows. These 449 rows are made up of the 440 unique actors and the 9 films, and this is where my actor_film_aes comes back in (and explains why I renamed actor and title variables to name). I can join my Node Data to this actor_film_aes to attach the weight and colour variables, and also create a new variable, type to denote if the node is a film or an actor (this distinction will be useful for plotting):
wes_network <- wes_network %>%
# add type to indicate if node represents a film or an actor
mutate(type = if_else(name %in% wes$title, "Film", "Actor")) %>%
# add the weightings to each film and actor
inner_join(actor_film_aes, by = "name")
wes_network## # A tbl_graph: 449 nodes and 518 edges
## #
## # A directed acyclic simple graph with 1 component
## #
## # Node Data: 449 x 4 (active)
## name type weight colour
## <chr> <chr> <dbl> <chr>
## 1 Isle of Dogs Film 4.9 #9986A5
## 2 The Grand Budapest Hotel Film 9.9 #FD6467
## 3 Moonrise Kingdom Film 5.5 #F4B5BD
## 4 Fantastic Mr. Fox Film 3 #DD8D29
## 5 The Darjeeling Limited Film 6.2 #FF0000
## 6 The Life Aquatic with Steve Zissou Film 7.7 #3B9AB2
## # ... with 443 more rows
## #
## # Edge Data: 518 x 2
## from to
## <int> <int>
## 1 1 10
## 2 1 11
## 3 1 12
## # ... with 515 more rowsThe Node Data now contains everything I need for the plot, so let’s switch to the Edge Data. This is done using the activate function. In the above, the Edge Data just consists of a from and to variable and has 518 rows. These relate to the 518 combinations of actors and films (i.e. it has the same number of rows as the initial dataframe). What I want to do is to change the colour of the edge based on which film it comes from. So for each row in the data I want to attach the film colour. The .N() function gives you access to the node data whilst working with the edge data, so I can take the colour variable just attached to the nodes and use it as a colour for each edge (I wish I could explain why I chose the from variable from the edge data, other than it just works!):
wes_network <- wes_network %>%
# now focus on the edges data
activate(edges) %>%
# add the colour attributed to the film nodes (from). N() accesses node data
mutate(edge_col = .N()$colour[from])
wes_network## # A tbl_graph: 449 nodes and 518 edges
## #
## # A directed acyclic simple graph with 1 component
## #
## # Edge Data: 518 x 3 (active)
## from to edge_col
## <int> <int> <chr>
## 1 1 10 #9986A5
## 2 1 11 #9986A5
## 3 1 12 #9986A5
## 4 1 13 #9986A5
## 5 1 14 #9986A5
## 6 1 15 #9986A5
## # ... with 512 more rows
## #
## # Node Data: 449 x 4
## name type weight colour
## <chr> <chr> <dbl> <chr>
## 1 Isle of Dogs Film 4.9 #9986A5
## 2 The Grand Budapest Hotel Film 9.9 #FD6467
## 3 Moonrise Kingdom Film 5.5 #F4B5BD
## # ... with 446 more rowsI now have everything I need in both the Node and Edge data in order to make the plot.
The Plot
Everything up to now has been with the plot (and the plotting method) in mind. ggraph is again by Thomas Pedersen and it’s also best to consult his blog posts on it (he outlines layouts, nodes and edges in 3 separate posts). If you’re familiar with ggplot2‘s ’grammar of graphics’ then you should feel at home with much of ggraph’s functionality, and it should now make sense why I’ve been setting up variables to be mapped to aesthetics in the plot. ggraph works just like ggplot2 in this respect. Some new geoms are introduced in ggraph to specifically deal with the node and edge data structure.
Firstly, after some trial and error looking for a pleasing placement of nodes, I settled on a seed (which I had been capturing so I could re-use it). There are several layouts available in ggraph, I chose fr after playing around with a few alternatives.
Now to the new geoms:
geom_edge_linkadds the edges (lines) connecting the nodes (dots). As detailed earlier, I have added theedge_colvariable to the edge data so I can colour the edges based on the film.geom_node_pointadds the nodes. I’m calling this 3 times in the plot:- The 1st call adds the film nodes (filtering on the
typevariable created earlier). I’m adding these on their own so I can set the size attribute for all film nodes. - The 2nd call adds all the actor nodes with a low alpha, all the same colour, but with a size based on their number of film appearances.
- The final call adds an extra layer of actor nodes only for those 22 actors appearing 3+ times (identified earlier), with a high alpha to highlight them in the plot.
- The 1st call adds the film nodes (filtering on the
geom_node_labelandgeom_node_textcan then be used to add labels. I’ve added a label for each film and then the text for the 22 most used actors. For the actor names, I’m using therepel = TRUEoption so all names have room to breathe.
As the colours are taken directly from the data, I use the scale_color_identity and scale_edge_color_identity functions.
I have liberally sprinkled the Futura font throughout the plot to make Wes proud, and carefully chosen some more colours for the title, background etc.
set.seed(3506)
# visualise network with ggraph
ggraph(wes_network, layout = "fr") +
# colour edges based on film node
geom_edge_link(aes(color = edge_col),
width = 0.8, alpha = .4) +
# colour film nodes based on the colours chosen from palettes. set 1 size for all nodes
geom_node_point(aes(filter = type == "Film", color = colour),
size = 10, show.legend = FALSE) +
# plot all actor nodes with a low alpha, size node based on no. of appearances
geom_node_point(aes(filter = type == "Actor", size = weight),
colour = actor_colour, alpha = 0.5, show.legend = TRUE) +
# plot only those actors appearing 3+ times with higher alpha
geom_node_point(aes(filter = name %in% most_used_actors$actor, size = weight, color = colour),
alpha = 0.8, show.legend = FALSE) +
# label the film nodes
geom_node_label(aes(filter = type == "Film", label = name, color = colour),
repel = FALSE, hjust = 0.5, vjust = 1.2, size = 3, alpha = 0.8,
show.legend = FALSE, fontface = "bold",
family = "FuturaBT-BoldItalic") +
# label the actors appearing 3+ times
geom_node_text(aes(filter = name %in% most_used_actors$actor, label = name),
colour = wes_palette("BottleRocket1")[7], repel = TRUE, size = 3,
show.legend = FALSE, fontface = "bold",
family = "FuturaBT-BoldItalic") +
# sets the node and edge colours based on the colours held in data
scale_color_identity() +
scale_edge_color_identity() +
# adjust actor node sizes for legend
scale_size_continuous(breaks = 1:8, name = "Number of Appearances", range = c(1, 8)) +
# set theme of graph - use the futura font
theme_graph(background = wes_palette("Chevalier1")[3], foreground = NA, base_family = "FuturaBT-BoldCondensed") +
# set all other themes and labels like any old ggplot
theme(legend.position = c(0.9, 0.25),
legend.text = element_text(colour = actor_colour, face = "bold", size = 12),
legend.title = element_text(colour = actor_colour, face = "bold", size = 12),
legend.title.align = 1,
legend.background = element_rect(colour = actor_colour, fill = wes_palette("Chevalier1")[3]),
plot.title = element_text(colour = wes_palette("GrandBudapest1")[2], size = 22, hjust = 0.5, family = "FuturaBT-ExtraBlack"),
plot.subtitle = element_text(colour = actor_colour, size = 16, hjust = 0.5),
plot.caption = element_text(colour = wes_palette("GrandBudapest1")[2], size = 12, hjust = 0.5),
plot.margin = margin(0.8, 0.1, 0.5, 0.1, "cm")) +
labs(title = toupper("The Films of Wes Anderson | A Network Analysis"),
subtitle = "Network showing all credited actors appearing in Wes Anderson's 9 feature-length films\nNames of actors appearing 3 or more times are shown",
caption = "@committedtotape | Source: IMDb.com")I finish the plot with theme and labs just as you would use in a regular ggplot2 plot. One final design choice was to centre the titles and captions, because symmetry is a must for our Wes. This gives us the end result (you may want to do a Wes Anderson style zoom-in):
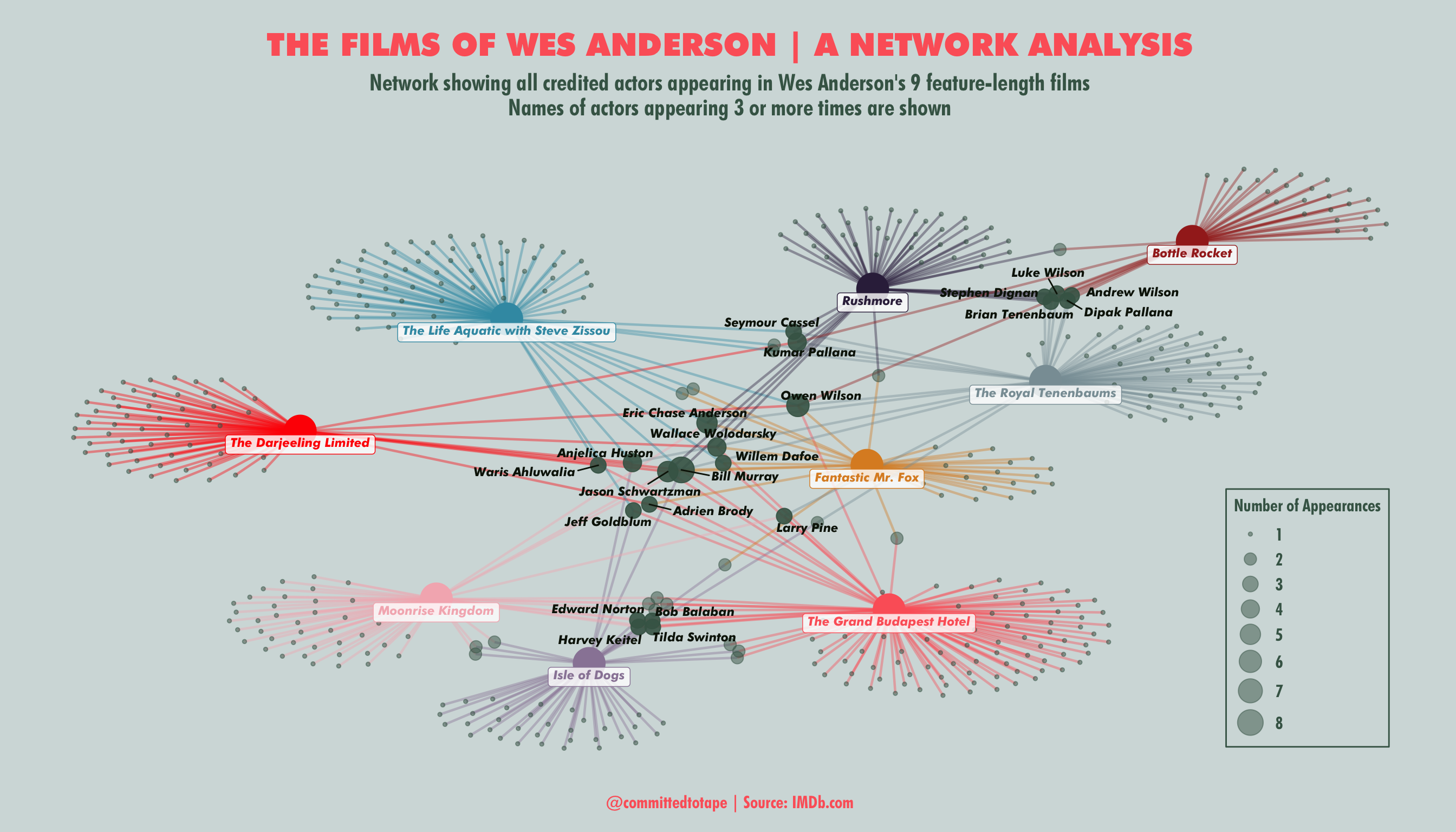
What does this tell me?
No surprises that Bill Murray takes centre stage, having appeared in all but one of the 9 films. Ably supported by Jason Schwartzman with 5 films. The plot has contrived to position the films in the rough order they were released, with the earliest films in the north-east corner, down to the latest films in the south-west. With 6 film appearances, Owen Wilson is centre-right as he hasn’t appeared in the last 2 films. There are then 2 distinct actor groups. The 5 actors (including Luke Wilson) who appeared in the first 3 films, and the 4 actors (including Tilda Swinton) who appeared in the latest 3 films. So although Bill Murray has been a constant since film 2, there has been a shift in actor base over the years.
The size of cast in each film is also represented, so we can see the big ensemble cast of ‘The Grand Budapest Hotel’ compared to the smaller casts employed for the animated films (‘Fantastic Mr Fox’ and ‘Isle of Dogs’) and his first film ‘Bottle Rocket’.
Closing
Considering I had zero experience of networks before attempting this, I’m pretty pleased with the result. It looks pretty much like what I had envisioned when I first had the idea. I still feel there may be a better layout which avoids the slightly cluttered centre of the plot, but I have my best network days ahead of me (hopefully). I’ve only scratched the surface of what tidygraph and ggraph can do, so will be looking for opportunities to develop my network skills further.
On a final note, I presented this visualisation at a Data Visualisation meet-up in Brighton towards the end of last year, organised by Peter Cook. In a Show-and-Tell segment at the start of the evening I gave a quick walkthrough of my process and what insight it provides. It was a great experience, with the audience seemingly engaged with it and asking lots of questions! One suggestion was to make it interactive using D3, so the nodes could be dragged about to form a cleaner look. I am intending to learn D3 at some point, so this gives me some more motivation!
Thanks for reading, now go forth and use the Wes Anderson colour palettes like there’s no tomorrow, because as Max said:
“I guess you’ve just gotta find something you love to do and then… do it for the rest of your life.”